MMTok
Multimodal Coverage Maximization for Efficient Inference of VLMs
🚀 Accepted to ICLR 2026 • Intelligent Vision Token Pruning for VLM Acceleration
Multimodal Coverage Maximization for Efficient Inference of VLMs
🚀 Accepted to ICLR 2026 • Intelligent Vision Token Pruning for VLM Acceleration
Vision-Language Models (VLMs) demonstrate impressive performance in understanding visual content with language instruction by converting visual input to vision tokens. However, redundancy in vision tokens results in the degenerated inference efficiency of VLMs. While many algorithms are proposed to reduce the number of vision tokens, most of them apply only uni-modal information (i.e., vision/text) for pruning and ignore the inherent multimodal property of vision-language tasks. To address this limitation, we propose to leverage both vision and text tokens to select informative vision tokens. We first formulate the subset selection problem as a coverage maximum problem. Afterward, a subset of vision tokens is optimized to cover the text tokens and the original set of vision tokens, simultaneously. Under the maximal coverage criterion on the POPE dataset, our method achieves a 1.87× speedup while maintaining 98.7% of the original performance on LLaVA-Next-13B. Furthermore, with only four vision tokens, it still preserves 87.7% of the original performance on LLaVA-1.5-7B.
Multimodal coverage maximization framework for intelligent token selection
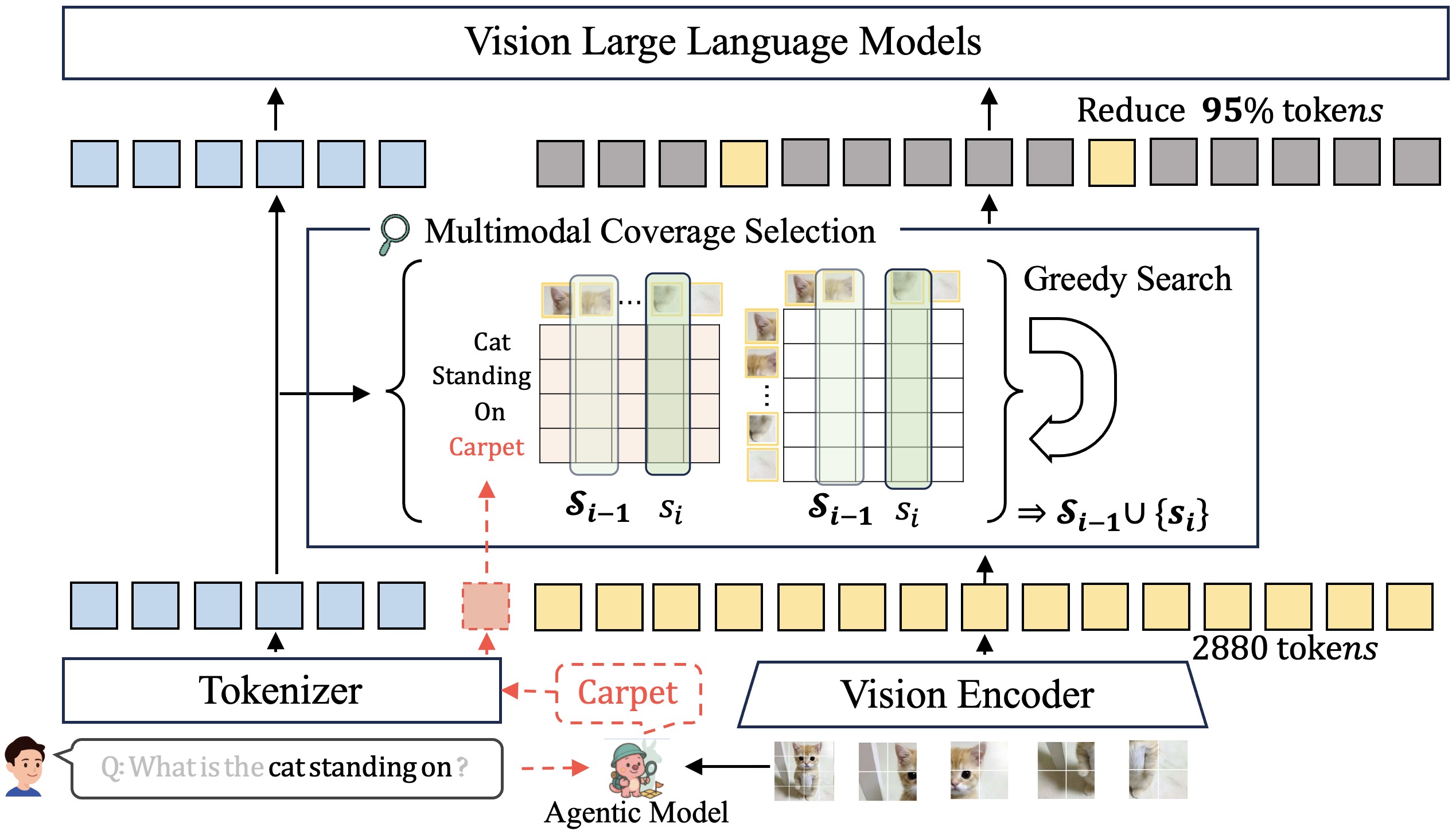
MMTok Architecture: Efficient vision token pruning through multimodal coverage maximization
Significant acceleration across multiple benchmark datasets
On H100 GPU (higher on other GPUs)
At highest prune ratio on LLaVA-1.5 & Next (7B & 13B)
4 tokens on POPE, LLaVA-1.5-7B
Comprehensive comparison with existing methods
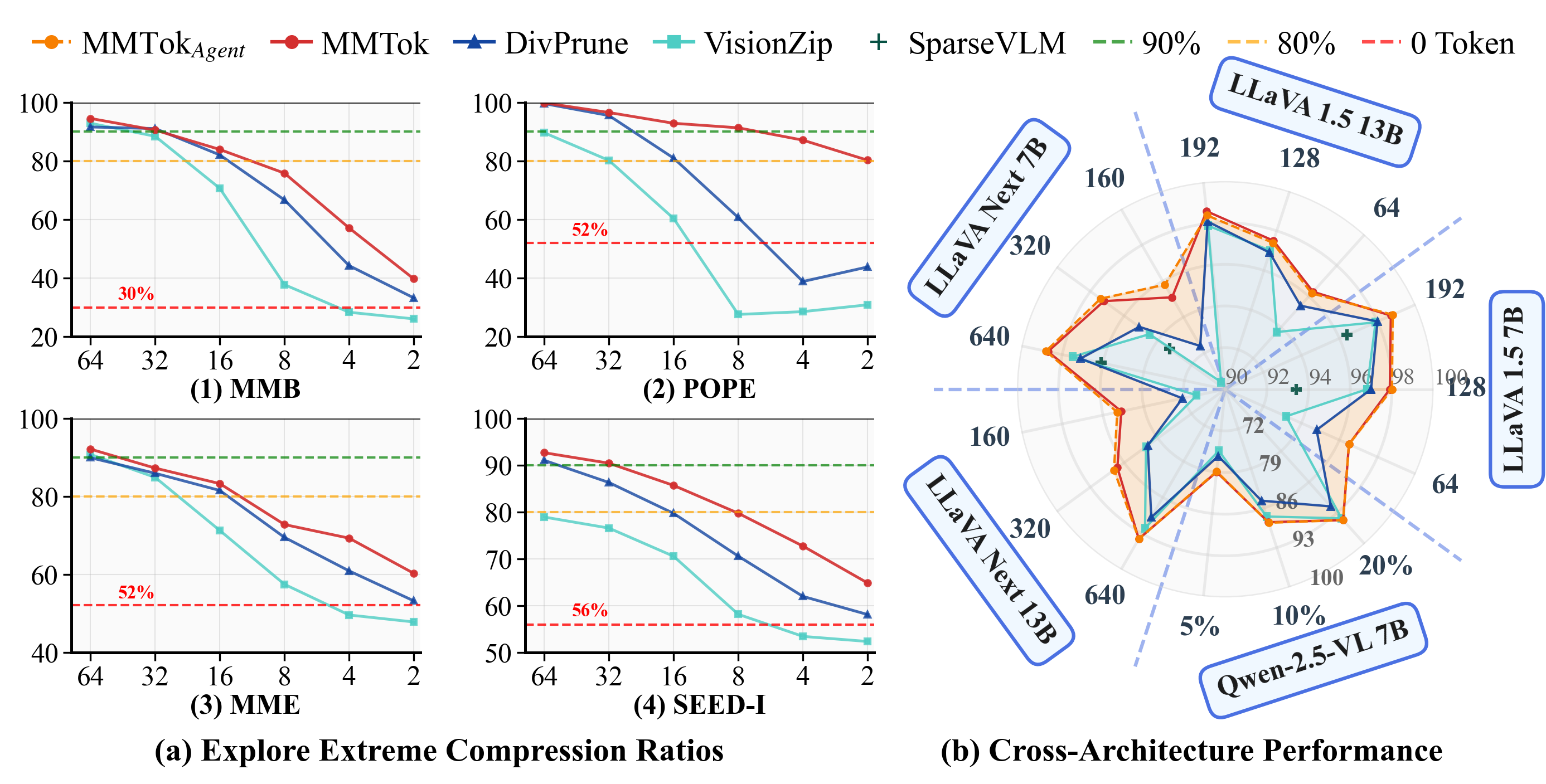
Performance comparison: MMTok results across multiple models and datasets
@misc{dong2025mmtokmultimodalcoveragemaximization,
title={MMTok: Multimodal Coverage Maximization for Efficient Inference of VLMs},
author={Sixun Dong and Juhua Hu and Mian Zhang and Ming Yin and Yanjie Fu and Qi Qian},
year={2025},
eprint={2508.18264},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.18264},
}We thank Zoom Communications for providing internship opportunities and research support. We also appreciate the multimodal learning community for providing comprehensive benchmark datasets and baseline implementations.
Special thanks go to our collaborators for their constructive feedback and support. In particular, Yebowen Hu offered valuable discussions and feedback, while Kaiqiang Song contributed many insightful discussions, extensive assistance with computational resource scheduling, and helpful exchanges that enriched our learning. We also acknowledge the support from Zoomies.
This work was supported by Zoom Communications, including computational resources. We gratefully acknowledge the generous support provided.
Have questions about our method or want to discuss the results? We welcome all questions, discussions, and constructive feedback!
Found issues with our implementation or have suggestions for improvements? Please open an issue on our GitHub repository.
Interested in collaborating or extending this work? We're always open to new research partnerships and joint projects.
Contact us: sdong46@asu.edu
GitHub Issues: MMTok Issues